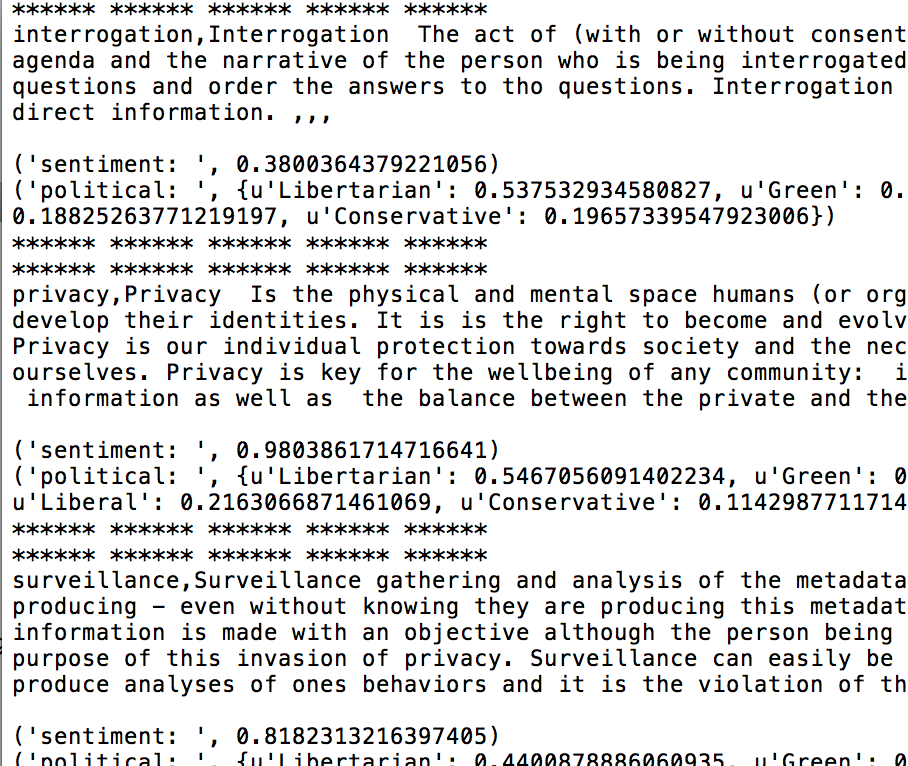
Interesting introduction to thinking a bit more deeply about how algorithms are engineered to learn about sentiment and meaning analysis. This small CSV data set was a set of definitions of 'privacy', 'surveillance', and 'interrogation'.
I analyzed each definition as a line using the Indico API for "political analysis" and also "sentiment." They seem pretty arbitrary but I suppose they gather the information from tags and things like that - but I think a point to explore further is: the internet is quite two-dimensional as a way to gather understanding of complex human sentiment and issues and tropes with a spatio-temporal history. If AIs are the children of humanity - is that any way to teach a child? Come now.
It is fun to play with the browser/GUI version and run words like "God" or "visage" or "face" or "help" (100% positive sentiment analysis) or "hurt" (1% sentiment analysis) though. https://indico.io
I just used some ngram examples I worked with a little in Python from Spring 2015's Python-based course Reading and Writing Electronic Text. I dabbled a bit in using the API to analyze each definition in a row as a line. Then I also analyzed each individual word which showed up more than twice in the text.